WannaCrypt, aka WannaCry, has been the Infosec story of the past couple of weeks. What was originally a humble ransomware became a newly retrofitted NSA-powered worm which spread recklessly, wreaking global havoc.
Fortunately, the proliferation of WannaCry came to a standstill when one of our security researchers, MalwareTech, working to collect intelligence for the Vantage Breach Intelligence Feed, registered a domain associated to the malware, ultimately triggering its “kill switch”.
What WannaCry does has been extensively documented by others, as seen in reports by BAE Systems, MalwareBytes, Endgame, and Talos. Rather than focusing on the technical functionality of the malware, this article will open a window into our recent experience with managing, mitigating, and tracking the propagation and evolution of the WannaCry outbreak, and the true extent of its reach.
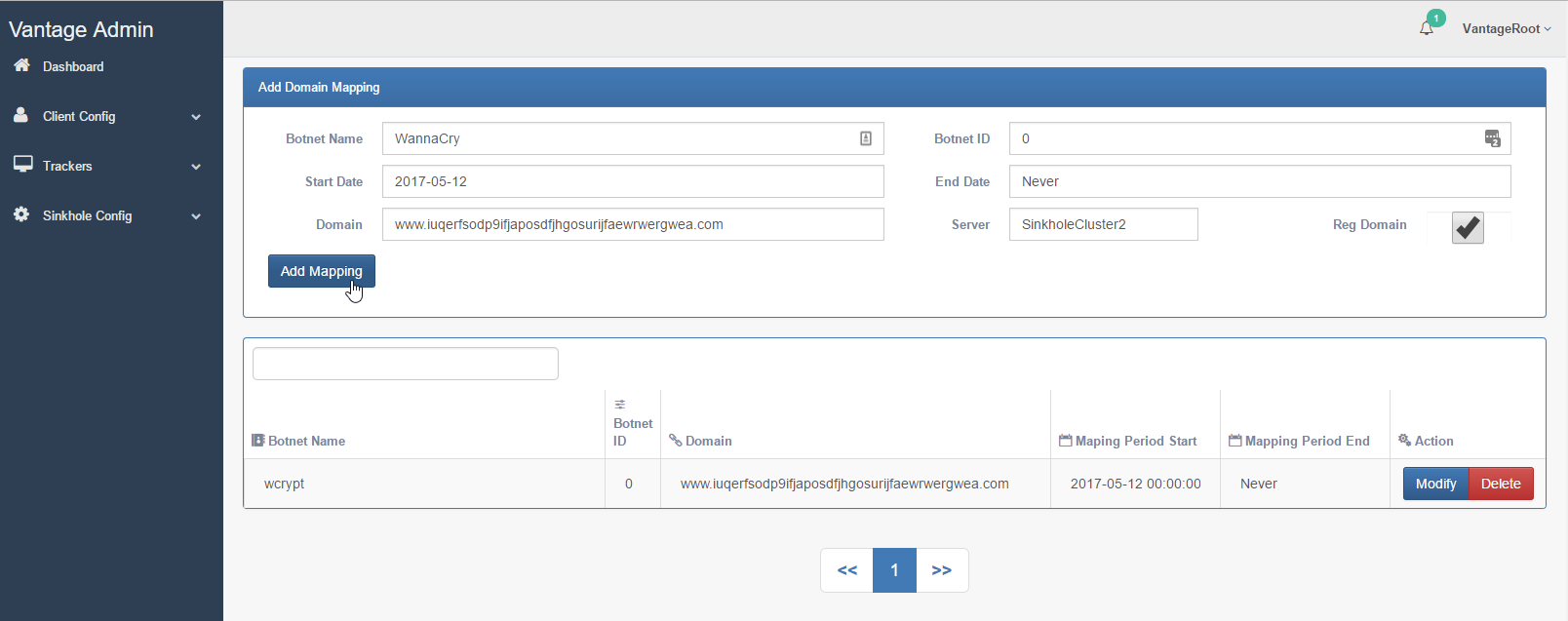
Vantage backend interface—the origin of MalwareTech's kill-switch registration.
The true magnitude of the attack
The widely reported 200,000 affected systems figure (presumably derived from Kryptos Vantage sinkholes summary), while somewhat accurate, is a conservative estimate. Surprisingly, the upper bound of queries made to our sinkhole may be a lot closer to the total number of unique IP hits, due to the fact that IPs with high hit counts can be correlated with a high number of infected machines sharing a public IP address explained in detail below.
Here we argue that the real number of affected systems, by assessing the sinkhole data, is in the millions, and we further estimate between 14 to 16 million infections and reinfections have been mitigated avoiding what would have been chaos, since May 12th. Our estimate is a few hundred thousand systems were disrupted by the ransomware payload until the kill switch was activated followed by a conservative 2 to 3 million affected systems which were not disrupted by the payload. Without the mitigating effect of the kill-switch, this number could have plausibly infected vulnerable systems well into the tens of millions or higher.
We observed WannaCry reached over 9,500 unique ISP and/or organization IP WHOIS registrations, 8,900 cities, 90 countries with a measurable (1000+ uniques) impact, and some infection traces reaching virtually all countries worldwide.
Before proceeding, we stress that “prevented infections” or “averted infections” are still successful exploitations by the WannaCry worm component. In other words, systems which were infected prior to the kill-switch were hit by the ransomware payload and therefore fully disrupted. This was the madness we all witnessed the first two days. However, systems exploited after the kill-switch was registered to Vantage platform were not fully disrupted. Therefore we qualify an infection as a system which was exploited by WannaCry, regardless whether or not it was benignly or actively disrupted by the ransomware payload.
Estimating botnet sizes is non-trivial task. But it is something we are experienced with at Kryptos, given we monitor hundreds of botnets every year and process approximately 100 million threat indicators per day. Typically, in order to estimate the number of infected systems behind a botnet, we triage domain specific knowledge of how the malware intrinsically operates and communicates within its code and augment this with data analysis techniques to produce “tells” about each of the connection variations. The result is a sanitized, more accurate, dataset for projections.
What is noteworthy about the WannaCry “kill-switch” domain is it is in fact just that, a “kill-switch”, and this is fundamentally different than a traditional Command & Control (C&C) domain. C&C are usually domain names intended to be “phone home” locations for an infected computer (bot) connecting a multitude of times, bound by some predetermined callback or phone home schedule.
However, the WannaCry kill-switch domain wasn’t intended as a method to call back home. Instead, it was meant to be contacted once presumably as a anti-sandbox feature gone wrong. As a result, the method to estimate the botnets figure and resulting assumptions can be treated differently than when computing a standard botnet. While not complete, the assumptions below are affirmations to more accurately estimate the reach of the WannaCry attacks and act as projections for future attacks in its likeness.
- Not a C&C: The kill-switch domain is contacted once only, when the dropper component starts.
- One and done: After initial infection, the dropper installs itself as a Windows service. Therefore we can expect one callback every time Windows starts up or reboots.
- Cease and desist: Each time WannaCry contacts the kill-switch, functionality will cease.
- Business continuity: Some charitable count of the average number of Windows machine reboots, 1 to 3 times per day, is assumed.
- Slowing down: WannaCry is programmed to terminate after 24 hours of SMB scanning, further ceasing activity until the infected system is rebooted.
The aggregate daily count for each unique IP address can therefore be used as a strong indicator of the number of potentially affected hosts. We also cannot ignore environmental factors that can skew the data either up or down in terms of infection count, such as:
- IP address churn (IP address change for the same infected system) should be accounted for from wireless hotspots, dynamic IP ISPs, and so on. In regions like India this is common practice and can create inflated assumptions about a country’s infection rate. IP churn will not immediately increase the perceived infected host count unless the host is also rebooted and still remains infected or is reinfected.
- During certain times of the collection period, Vantage servers were hammered by DDoS attacks; this could have affected our data. We worked to filter out these periods (where we knew it was happening), and used other internal filters to avoid adding DDoS data and irrelevant accesses to the final figures.
- Reinfection of the same systems will occur when one or more hosts infected persistently within the network and reinfect other systems on reboot.
- Newly infected systems will not be infected persistently and not attempt spreading activity.
Our sample of roughly two weeks, after data sanitizing processes are introduced, confirm approximately 727,000 unique IP addresses were likely WannaCry victims. In a large number of cases, each unique IP address would have hundreds to tens of thousands of requests per day! Although it is conceivable that some corner cases people are simply hammering the domain (see the section below titled “Protecting the protectors”), the data still suggests what everyone assumed, there are many more systems, presumably behind NATs, VPNs, etc, that are infected and continue to be reinfected.
To be clear, when we observe a single IP with multiple hits in the same day, that this was not the result of a single machine rebooted hundreds of thousands times per day, but more reasonably that there are multiple persistent infections (prior to kill switch or other reasons) and these are new or reinfection attempts behind a particular IP address in question.
The above graph illustrates our point by with a vertical bar graph distribution of the top most affected countries by unique IP address count. Each country is stratified by number of hits per IP. We can see that China absolutely dominates the high counts, but nevertheless most other countries too have a diverse distribution of hit count ranges. This suggests some organic behavior that we expect.
Here we look at the total hits to the sinkhole at the height of the attack over the most active initial two day period after MalwareTech activated the kill-switch. WannaCry traffic accounted for just around 2% of total traffic compared to the total malicious traffic of other botnets we monitor in the Vantage sinkhole. From a volume perspective, this had virtually no effect to our botnet monitoring platform. But the story is not over, in terms of magnitude something completely different can be uncovered. We pivoted towards analyzing its magnitude, by observing unique IP addresses in 30 minute intervals depicted below.
Here we see a noticable increase in the surface, now accounting for about 5% of the total unique IP addresses we are monitoring for this period. Looking again at the graph, we measure approximately 100,000 WannaCry unique IP addresses detected during same two day outbreak. What we realized at this point was the traffic volume is still not accurately depicted.
Why?
Because these botnet comparisons are infact C&C based botnets that phone home regularly, some of which have very high frequencies at multiple callback times per minute. Historically, our stats tell us that the largest botnets range between 1.5 and 3 million unique IP addresses for periods measured in weeks or months. When we normalize this under the assumption that the overall infection rate is the sum of unique IP address hit counts in a given day, and minding our other assumptions (reboots, etc), it turns out that within 48 hours WannaCry potentially became one of the largest worm outbreaks we have seen, rivaling botnets which have been in operation and growing for years.
What this tells us is the real reason WannaCry was so dangerous, velocity. Velocity was so high that within one week it could propagate more than every spam campaign, exploit kit, website hijack, you name it attack type using a single vulnerability. We can only imagine the damage this worm would have unleashed had it been used while ETERNALBLUE was still a zero day vulnerability (not fixed by Microsoft). To put this in perspective, that was only a few months ago on March 14th, 2017!
Like other cyber security followers, we also conjectured what could have caused so many infections in China. We knew some of these elements could have been related in one way or another to:
- Insecure internet facing firewall rules (open 445 ports)
- Pirated copies of Windows
- Previously reported low adoption rates of Windows 10 in China
…other supporting root cause conjectures are many (patch management, unmanaged systems etc). And then we noticed perhaps another explanation a few days out, in India but primarily China a sharp jump during what we consider the fallout period:
What we can see is a steady flow in most countries, but clearly China has a massive jump. While we considered several plausible explanations as to why this persists and is even growing—for example could this equate to a potential DDoS—this does not seem to be the case. The jump came from a variety of specific ISPs which had in prior days been affected consistently, but had not previously had such high counts. Moreover, within the ISPs in question, infections were spread throughout hundreds of IP addresses with just 5-50 queries in a day, and just over a few thousand unique IP addresses. This is a relatively reliable growth for a 24 hour period. With a DDoS attack, we expect to see very high numbers that repeat for predictable continuous periods (high density periods) from a multitude of regions. We also considered someone attempting to skew data, but the data didn’t support the hypothesis.
We end this section with some additional caveats that could have had an some measurable impacts to our estimates:
- Day to day counts can be relatively skewed due timezones and reboots.
- Security researchers and automated analysis systems contributed (negligible).
- Some firewall operators or ISPs may have blacklisted the domain for periods of time, unwittingly placing systems at greater risk.
Current state of the attack
At this point in time most IT administrators feel some sense of relief thanks to the kill switch, but we must remark on the origin of the still-growing number of hits we are receiving. Consider that there are essentially three ways that our sinkhole may be getting queried:
- A machine has just been exploited using the ETERNALBLUE / DOUBLEPULSAR payload embedded in WannaCry, and is running the dropper for the first time (strictly speaking, not necessarily the first time, close enough).
- A machine may have been infected with WannaCry prior to the kill-switch being available, and will query the domain with each reboot.
- The domain is query directly by an unrelated means, like a browser.
As mentioned before, we filter most of 3, but the interesting thing is that the numbers of hits we are getting suggest that most kill-switch contacts right now are the result of new exploitations and reinfections of systems which have yet to be patches. As machines get patched, we expect these numbers to dwindle.
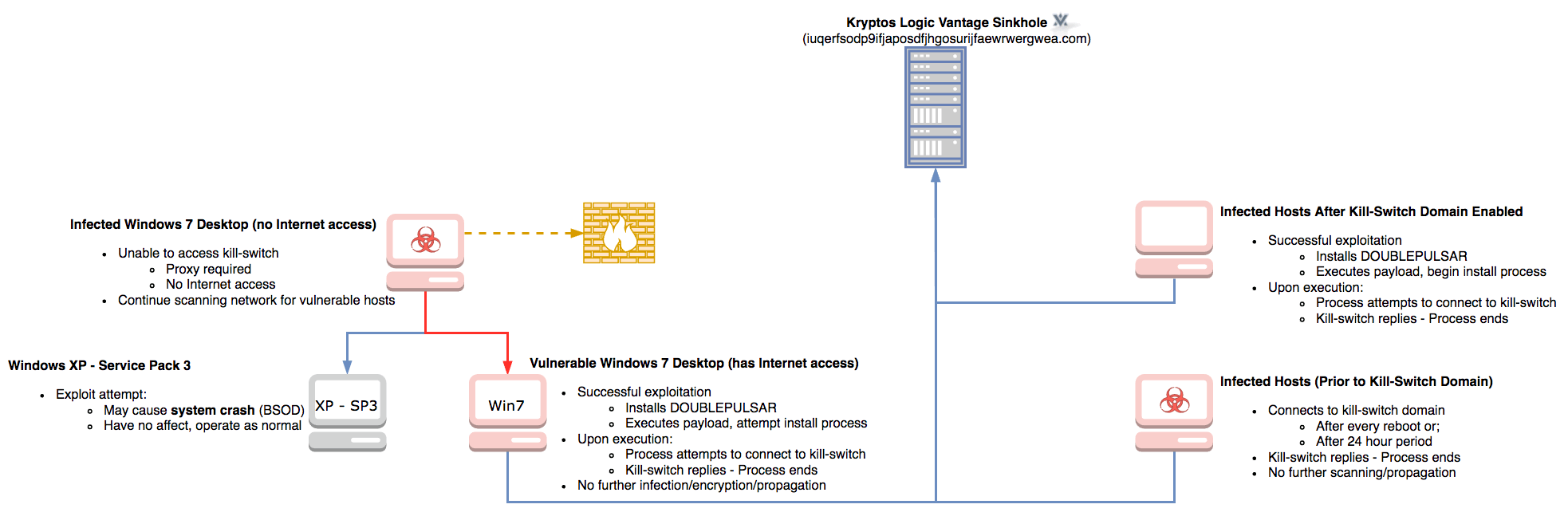
WannaCry infection flow.
We observe a very high infection rate in China and a relatively steady infection pattern throughout most countries. This could mean that most of these systems are assumed to be safe by whoever manages them (unmanaged?), since there is no visible fallout from infection when the kill-switch is activated. But the reality is these systems are not safe. If left unpatched, the next worm outbreak will have or already have infected these systems.
There are two points regarding Endpoint Detection & Response (EDR) and Anti-Virus (AV) we would like to introduce as people evaluate the aftermath and state of this attack. Pragmatically speaking, EDR systems are very good for forensics and analysis of historical data, with some potential for good detection capabilities. We understand them very well as we developed our own called Tactics. Notwithstanding the attack surface it introduces, AV is possibly one of the only scalable defenses available in the case of this easily detected type of outbreak. Even incomplete, it could at least stop the attack based on signatures as the authors of WannaCry all but abandoned the attack. It would even further warrant AV usage had WannaCry used a zero day exploit, as then the only reasonable endpoint defense option during the outbreak period for most would still be AV heuristics.
So what’s our point? We think at this point the reinfection and infection rates we are seeing could be attributable to systems which do not use up to date or any AV whatsoever. Had they had working AVs—most of which by now already block WannaCry—we should not see the kill-switch be queried at all. Thus, all attacks we see today are probably a result of unmanaged or poorly managed systems that are not patched and up to date, as well as have outdated or no AV solutions. Given that it has been reported that Windows 7 does not have adequate protection out of the box, our data may well support the case.
Who started it?
A few days after this whole thing began, the story took a new turn. Neel Mehta (who you might remember from Heartbleed) tweeted what seemed like convincing evidence that the authors of WannaCry are somehow linked to the so-called Lazarus group—a group sometimes linked to North Korea—and responsible for, among other things, the 2014 Sony hack and last year’s Bangladesh bank burglary.
The evidence can be summarized as follows: an earlier variant of WannaCry, from February this year, was found to share a particular function with another piece of malware, dubbed Contopee, which is linked to the Lazarus group. So what does this mean?
Some were naturally skeptic. Code sharing is nothing if not natural given how much code is routinely copy-pasted from Stack Overflow, Github, you name it. So does this common function do in each of the malware samples, and what is its significance?
For context, here is a rough C++ reconstruction of the function in question, taken from 9c7c7149387a1c79679a87dd1ba755bc at 0x402560:
| |
In short, this function is part of a mock implementation of TLS 1.0 used to make traffic look like TLS communications. In particular, this function creates the ClientHello record, which is the first packet to be sent when setting up a TLS connection. The table is a list of standard TLS ciphersuites, randomized for each packet, and which can be mapped to more readable names by looking at the corresponding OpenSSL source code.
There are clues in this very snippet that this is not really TLS. For one, the ciphersuites are not respected; the encryption is completely homebrewed. Secondly, the ClientHello record in itself contains clues that this is not really TLS:
- The record size is encoded in little-endian format, instead of big-endian. This will render the record malformed by a real TLS listener.
- The extension length field is missing. Even if there are no extensions, it should be present and 0.
Of course, if you’re familiar with the Lazarus group, you might remember Operation Blockbuster from a while back. In their report, researchers detailed how malware from the Lazarus group makes its traffic look like TLS, and their observations closely match what we see here. This is why this find by Neel Mehta is so interesting—this is not some random library code that happened to be in common between two binaries. It is instead a laser-focused piece of code designed purely to pass malicious communications off as legitimate (and presumably impossible to man-in-the-middle).
This leaves us with two options: either the authors of WannaCry did have access to some of the Lazarus group’s source code and/or toolkits, or they did find out about this method and thought it was worth trying out. Considering the relative simplicity by which this can be reverse-engineered and reimplemented by a third party, it’s not unreasonable.
Perhaps here lies the scariest aspect of this whole thing: a single individual can leverage publicly-known resources—in this case, the Equation Group tools leaked by ShadowBrokers—to cause as much damage as a nation-state attack would. This should, and might be for some, a wake-up call to the state of computer security, but perhaps more importantly, security posture. This was an entirely avoidable disaster.
Correcting the Record
While many were drawn to the narrative of the accidental hero and much preferred the pseudonym MalwareTech, the fact is MalwareTech—who everyone is emphatically proud of at Kryptos Logic—was indeed doing his business as usual, fighting and understanding botnets for the Vantage program he runs. Make no mistake, this was no accident; it was just not initially assumed that the domain was a kill switch. You can’t predict a hero.
Further reports surfaced about a day in with new samples emerging containing different kill-switch domains. This was immediately questioned, in particular as to what the point was. We thought the obvious question anyone else would “why is there still a kill switch in the first place?”. Occam’s razor suggests that someone with basic skills edited the original binary and put in a new domain. These particular domains had very limited exposure and spreading. Almost all the impact occurred on the original domain, which Kryptos Logic is continuing to monitor.
Anyone could just have easily patched out the kill-switch and re-released the malware samples if damage or money was the agenda, but whoever released the second and subsequent samples must have intended for other researchers to find the “new” kill-switches. It is disturbing to consider the full recklessness and carelessness of these actors, especially knowing this had affected hospitals and could have (or may have) caused loss of life. Nevertheless, these particular domains had relatively limited exposure and their spreading was almost nonexistent as most organizations had begun mitigations and lockdown procedures, but more important researchers had immediately sinkholed these rogue domains before the samples could propagate and scan for vulnerable hosts.
Protecting the protectors
First came Mirai, the same botnet that took down Dyn DNS, and with it high profile websites and services (remember no Netflix, Github, or Amazon?). It was the first blatant attack to target the kill-switch. We managed to withstand the attack since our infrastructure has been continuously expanding thanks to another Kryptos Logic security researcher and unsung hero, 2sec4u, whose immense efforts and assistance to MalwareTech kept kill-switch lights on! Now, this was not our first rodeo with DDoS, so we had anticipated this would happen on the sinkholes. What we didn’t predict is how many times and by how many different attacks it would occur. As a result, we placed our efforts on maintaining the sinkhole uptime and the kill-switch domain for the first few days.
Here are just a sample of some of the attacks we experienced:
Going into Saturday, after Vantage team had already pulled an all-nighter, we got hit by another HTTP flood (OVH thanks for keeping up with us!). If that wasn’t enough, here are some more DDoS attempts:
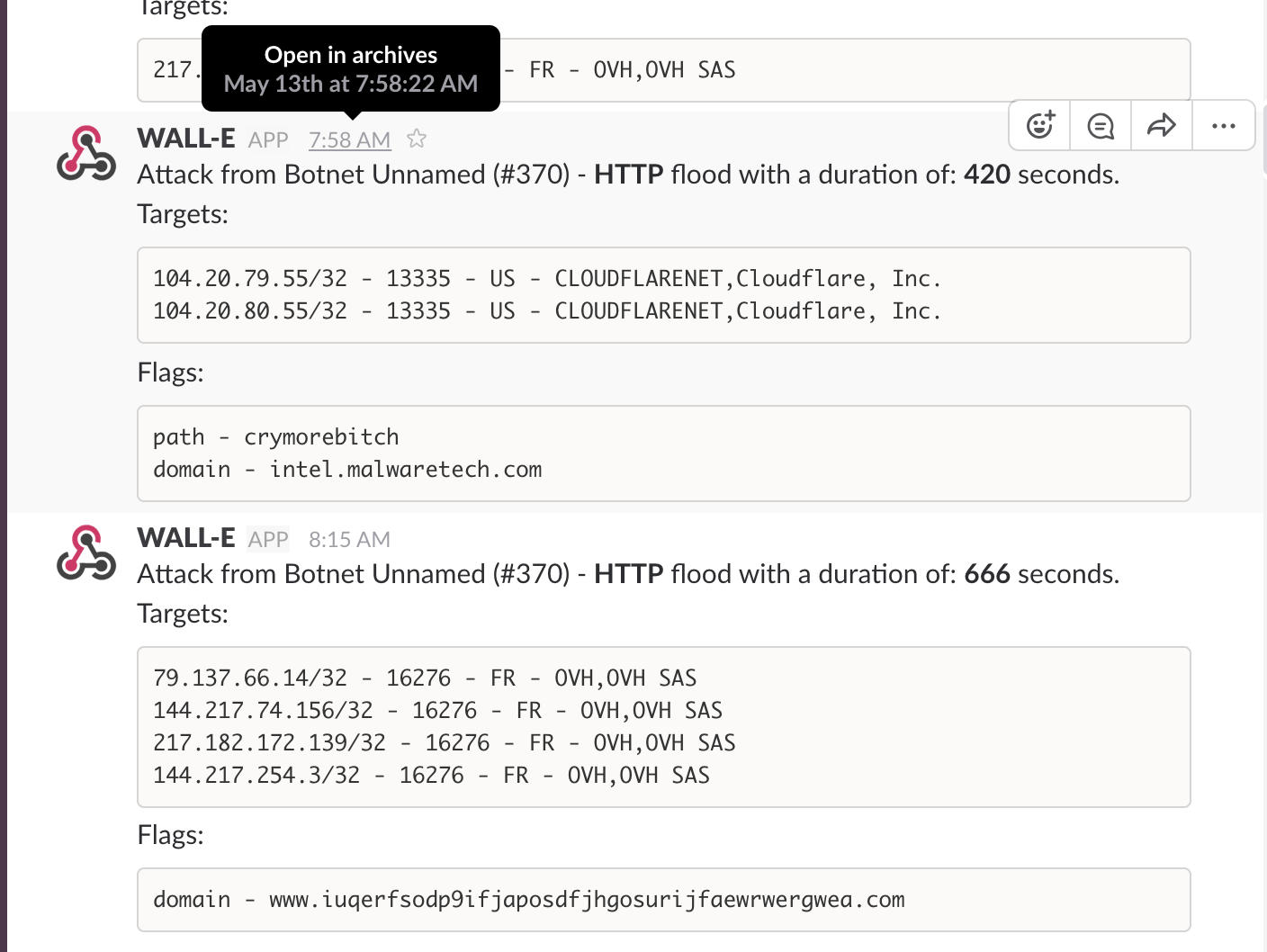
Flood after flood.
Had the Kryptos Logic Vantage infrastructure gone down during the crucial 48-hour outbreak period, it’s plausible the rest of the world could have in turn been further impacted (since the kill-switch would have turned back off) by the unmitigated propagation of WannaCry.
As there were multiple contingency plans and backup support from companies like Cloudflare and Amazon (and many others), had we needed to make changes we could. If juggling this wasn’t enough, the team were fully occupied dealing with media outlets attempting to “dox” MalwareTech and responding to law enforcement requests for regular exports of the data to provide to CERTs worldwide to react accordingly.
We would like to once again give all due credit to 2sec4u and MalwareTech from the Vantage team, to whom we are all indebted for keeping things running smoothly.
Operating Systems and Threat Simulations
WannaCry’s primary (and, perhaps, only) method of propagation is via the MS17-010 SMB vulnerability. The SMB protocol is used by Windows machines to communicate with file systems over the network. An infected machine will propagate the infection to other hosts on the local network vulnerable to MS17-010.
The exploit code used by WannaCry, ETERNALBLUE and DOUBLEPULSAR, was designed to work only against unpatched Windows 7, Windows Server 2008, or earlier operating systems. Windows 10 and newer are reportedly not vulnerable to ‘ETERNALBLUE’.
There have been various debates with regards to WannaCry’s ability to successfully infect unpatched Windows XP hosts on a network. We decided to test various scenarios using the following operating systems, all of which are vulnerable to MS17-010:
- Windows XP with Service Pack 2
- Windows XP with Service Pack 3
- Windows 7 64 bit with Service Pack 1
- Windows Server 2008 with Service Pack 1
Our primary infection vector was a Windows 2008 Server with Service Pack 1, where the WannaCry binary was manually executed on the host.
Upon execution, the ransomware would execute its usual methods for infection and begin encrypting the files on the local filesystem. While encrypting files it will also begin targeting vulnerable hosts on the network for MS17-010 and for hosts with DOUBLEPULSAR installed.
Our first setup was to test propagation via the ETERNALBLUE exploit (MS17-010). The primary infection found the hosts and attempted to exploit it via SMB, this surprisingly turned out to be unsuccessful on Windows XP, and the infected host then attempted to send its payload via DOUBLEPULSAR which failed as the targets clean installs.
- Windows XP with Service Pack 2
- No infection
- Windows XP with Service Pack 3
- Random blue-screen of death (BSOD) but no infection
- Windows 7 64 bit with Service Pack 1
- Infected after multiple attempts
- Windows Server 2008 with Service Pack 1
- Could not replicate infection, but reported exploited
As ETERNALBLUE exploits a heap overflow, successful exploitation is nondeterministic and requires multiple attempts. WannaCry gives up on an IP after 5 attempts.
The next step was then to manually backdoor each of the test systems with DOUBLEPULSAR. The primary infection machine again was locally executed and attempted to drop the payloads on the DOUBLEPULSAR compromised hosts. Windows 7 64 bit with Service Pack 1 was successfully infected and began the process of encryption and propagation again. However, it was found that both Windows XP hosts kept blue-screening and rebooting without any infection occurring.
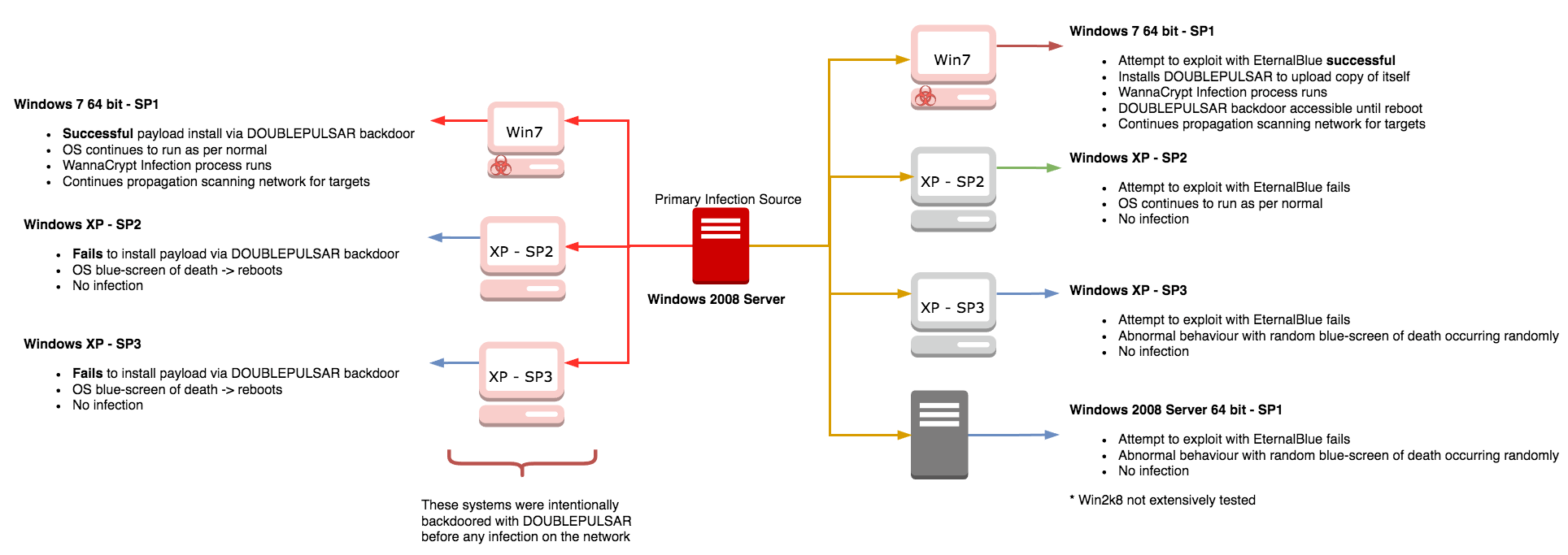
WannaCry infection tests.
It must be noted however that Windows XP is not safe from infection when the WannaCry binary is executed locally on the host. The ransomware will install successfully and encrypt the host’s files. That being said, since the main infection vector here was the SMB exploit, it seems like XP did not contributed much to the total infection counts. To be clear, the Windows XP systems are vulnerable to ETERNALBLUE, but the exploit as implemented in WannaCry does not seem to reliably deploy DOUBLEPULSAR and achieve proper RCE, instead simply hard crashing our test machines. The worst case scenario, and likely scenario, is that WannaCry caused many unexplained blue-screen-of-death crashes.
Two months ago in one of the security projects we are bringing out of stealth in June, an enterprise threat and risk simulator, we had embedded DOUBLEPULSAR into our simulations. We made this simulation to illustrate the impact and provide organizations the ability to test their security tools and readiness for such an attack. We think this exemplifies the reasoning for such a solution after these attacks. Below is a excerpt of threat simulation interface which was used to prepare some of our clients ahead of these attacks.
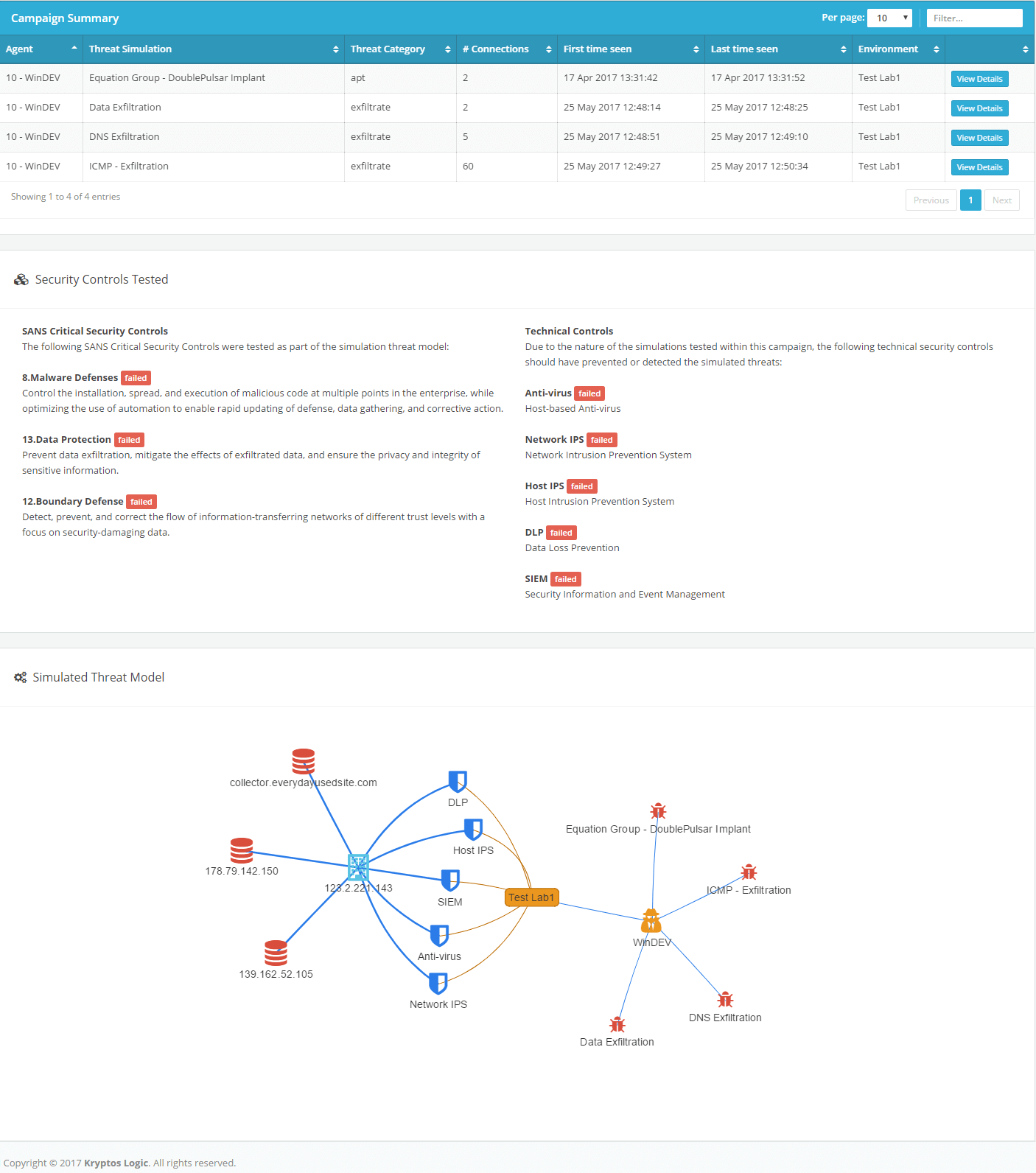
Threat simulator interface.
Ultimately this tells us, regardless all systems are vulnerable, readiness and security training are an area which can help many organizations, both small and large, to find out the most critical weaknesses they should focus their limited resources on.
What’s next?
This kill switch is a design foible that gave organizations and people worldwide borrowed time, but the immunization process has yet to continue, this and other attacks are far from over – yet are very preventable. For example, in the chart below we see a single (redacted) organization affected by this attack. What is most interesting is it was not affected in the first 72 hours, instead we see 1 single infection which started on the 18th, by the 25th it had seen close to 150,000 hits related to infections and reinfections. We could conjecture this is at least 15,000 machines and theoretically up to 150,000 machines. Essentially, if the kill switch had not thwarted WannaCry at this organization, it could have easily experienced a damage campaign to that similar to the worst reported attacks.
It maybe possible, this and many organizations realized remediation efforts would be easier by opening up their networks to this particular kill-switch, which could provide a smoother environment for remediation efforts since WannaCry would access the kill-switch and cease malicious activity. However, let us be clear, this is no outlier case. Kryptos has observed thousands of enterprises who have yet to take preventative measures, even reactively, to combat their risks. We can only speculate the urgency may not be readily apparent to these organizations because the kill-switch has prevented the damaging payload from triggering in their environments and they are completely unaware of the impact and risk they currently are exposed to.
Moreover, to reinforce this point, we look at the trend of the most infected countries and can see at a global level we are seeing new and recurring infections due to unpatched systems.
The reality is quite straightforward, this is still spreading and likely finding new unpatched systems globally.
Acknowledgments
It behooves us to mention that later into the week we got fantastic and free support from both Amazon and Cloudflare for any resources at their disposal. We did use some of these resources in the later stages of the attack (as it died down) and thank them for the assist!
We would also like to commend the Associated Press, USA Today, ABC, Reuters and many others for their professionalism in their dealings with us throughout this crisis.
It should also be noted we had a huge outreach from the security community who also offered similar assistance, those will be specifically thanked in a later time when we have completed a comprehensive list. Finally, thanks to the FBI and NCSC which were instrumental in getting the word out and IOCs needed to deter further impacts. Stay tuned for more information; we plan to testify and release updated data to House Science, Space, and Technology Committee. Finally, we deeply respect the efforts of those who spent sleepless nights coordinating with Kryptos Logic team to suppress this attack.